- Published on
A Survey from Algorithms to Systems
- Authors

- Name
- alan
Towards Efficient Generative Large Language Model Serving: A Survey from Algorithms to Systems论文
- 论文下载地址
概述
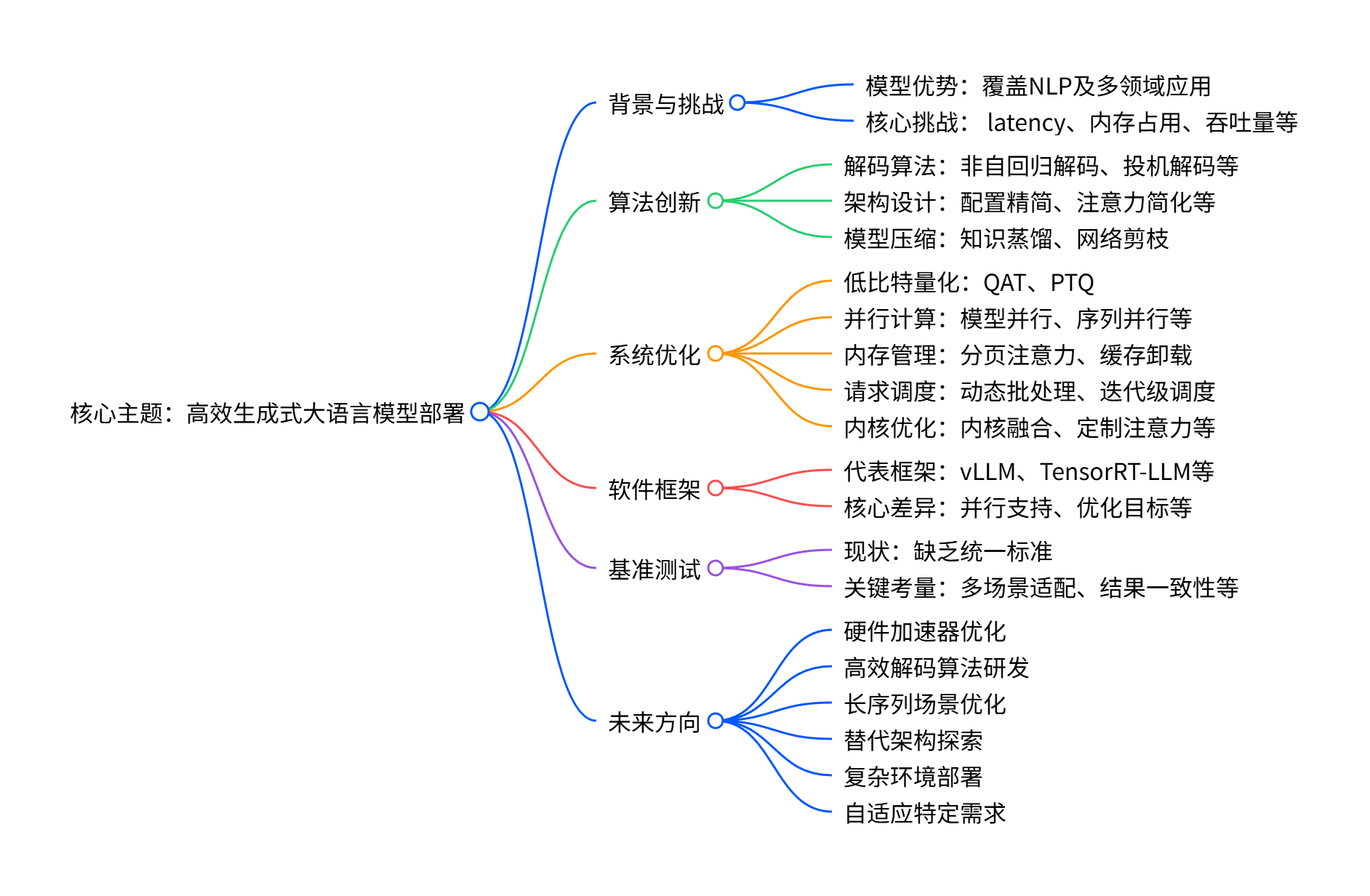
这篇文章写怎么让生成式大语言模型(比如 GPT、LLaMA 这些)跑得又快又省资源,从算法和系统两个层面总结了现有方法、工具和未来方向
本文主要聚焦与GPU,虽然我是聚焦边缘端推理的,但是可以学习一下。
一、核心背景:大模型好用但 “难伺候”
生成式大语言模型特别厉害,能做翻译、写文案、答问题甚至编程,但有个大问题:部署的时候特别 “费钱费资源”。
- 要么反应慢( latency 高),实时聊天、智能助手这些场景用着卡;
- 要么占内存大(模型参数多),普通设备根本装不下;
- 要么处理不了太多请求(吞吐量低),多人同时用就崩;
- 还得在 “跑得够快” 和 “回答够准” 之间找平衡,不能顾此失彼。
二、解决思路:从 “算法” 和 “系统” 两方面优化
就像给大模型 “瘦身提速”,分两大方向下手,双管齐下:
1. 算法层面:改模型 “做事逻辑”,让它少走弯路
- 优化解码方式:比如不用逐字生成(非自回归解码)、先猜后验证(投机解码),或者简单问题早结束计算(提前退出),省时间;
- 简化模型结构:比如减少注意力计算的复杂度、让不同层共享计算结果,或者只激活部分 “专家模块”(MoE 架构),少做无用功;
- 给模型 “瘦身”:比如把大模型的知识 “蒸馏” 给小模型、剪掉没用的参数(剪枝),让模型变轻巧。
2. 系统层面:优化 “运行环境”,让硬件物尽其用
- 降低精度存储:用更少的比特(比如 INT8、INT4)存储模型参数,不怎么影响效果还省内存;
- 多设备并行计算:把模型拆去多个 GPU / 设备(模型并行、序列并行),或者用云服务器、分布式设备分担压力;
- 智能管理内存:比如给缓存 “分页”(PagedAttention),避免内存浪费,还能把暂时不用的数据放到 CPU / 硬盘,缓解 GPU 内存压力;
- 合理安排请求:比如把相似请求打包处理(动态批处理)、给紧急请求优先权限,提升整体处理效率;
- 优化计算核心:定制专门的计算逻辑(核函数融合、定制注意力计算),让 GPU 跑得更高效。
三、实用工具和评估:现有框架和怎么比好坏
- 主流框架:比如 vLLM(靠分页缓存提吞吐量)、TensorRT-LLM(NVIDIA 的,支持多并行)、FlexGen(单 GPU 也能跑大模型),各有侧重;
- 评估难题:目前还没有统一的 “跑分标准”,因为模型、硬件、请求量不同,很难公平对比,需要考虑 latency、吞吐量、成本等多方面。
四、未来方向:接下来重点研究啥
- 定制硬件:设计更适配大模型的芯片,让计算和存储离得更近,跑得更快;
- 更高效解码:比如优化投机解码,让 “猜测” 更准、验证更快;
- 支持超长文本:解决长文档处理时的内存和计算压力,避免 “记不住中间内容”;
- 新模型架构:探索替代 Transformer 的结构,找更高效的计算方式;
- 复杂环境部署:比如在边缘设备、分布式网络上部署,兼顾速度和成本;
- 自动适配需求:让模型能根据不同场景(比如多轮对话、推理任务)自动优化。
论文中提取的有用信息
因为作者本人是边缘推理编译器开发人员, 所以只从论文中提取对我来说有价值的信息,浓缩收集整理在下面。
1. 概要
主要是围绕:
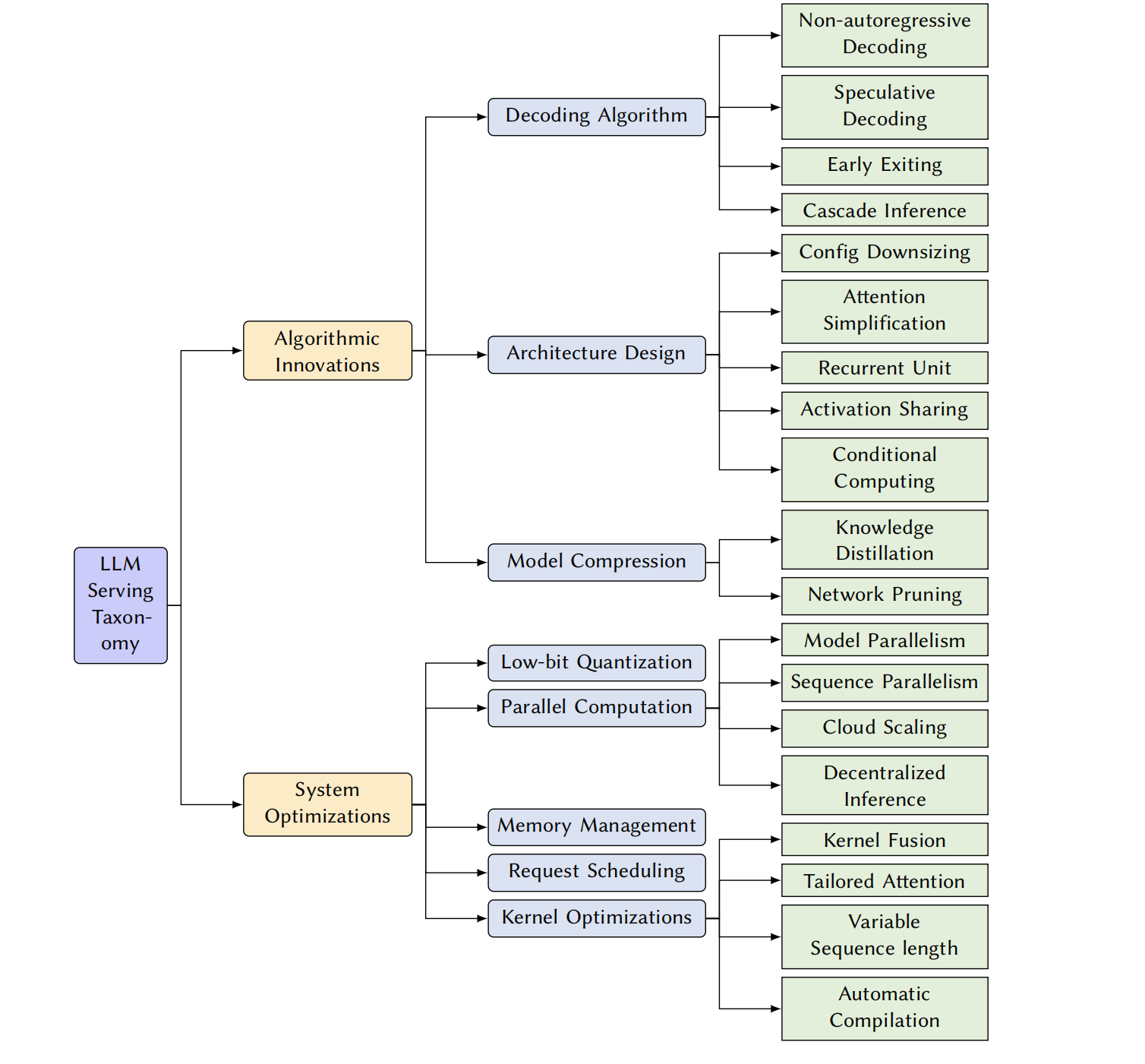
The primary objective of this survey is to provide a comprehensive overview of the latest advancements in LLM serving and inference. We will systematically review and categorize the existing techniques based on their underlying approaches, highlighting their strengths and limitations. The survey will cover a broad range of methodologies, encompassing decoding algorithm, architecture design, model compression, low-bit quantization, parallel computation, memory management, request scheduling, and kernel optimization.
2. 主要的模型结构
- 注意力结构
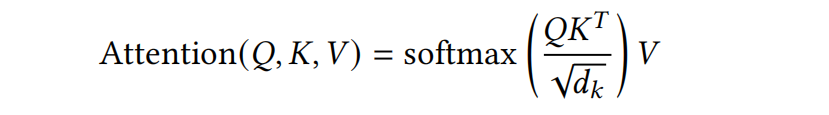
- Feed-Forward Network(FFN)
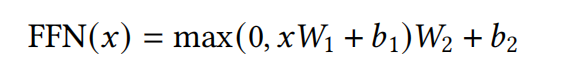
以上结构目前基于transform结构的主要的挑战有:
- 延迟和相应时间
- 需要优化算法和系统架构
- 内存占用和模型大小
- 模型压缩 & 系统优化
- 可扩展性和吞吐量
- 并行计算, 请求调度
- 准确性和效率之间平衡
3. 其他边缘端设备的一些论文
关于背景描述这块,我们还可以关注其他的边缘端设备的一些论文 :
TPUs [157 ],
FPGAs [ 336 ],
mobile and edge devices [79],
ASICs [ 239 , 367 ]
other emerging AI chips from various manufacturers (e.g., Apple M2 Ultra [172], AWS Inferentia [6], SambaNova [28], Cerebras [81], Graphcore IPUs [ 16])
| 分类 | 设备类型 | 标注编号 | 论文标题 | 核心贡献 | 发表时间 |
|---|---|---|---|---|---|
| 非自回归解码综述论文 | - | [319] | A survey on non-autoregressive generation for neural machine translation and beyond | 系统总结非自回归生成在神经机器翻译及其他领域的最新进展 | 2023 |
| 非自回归解码相关论文 | - | [110] | Mask-Predict: Parallel Decoding of Conditional Masked Language Models | 提出掩码预测方法,通过打破词依赖实现并行解码,加速机器翻译 | 2019 |
| - | [117] | Non-autoregressive neural machine translation | 首次提出非自回归神经机器翻译框架,奠定并行解码研究基础 | 2018 | |
| - | [122] | Non-autoregressive neural machine translation with enhanced decoder input | 通过增强解码器输入,优化非自回归翻译的输出质量 | 2019 | |
| 半自回归解码及延伸技术 | - | [111] | Semi-autoregressive training improves mask-predict decoding | 提出半自回归训练方法,提升掩码预测解码的翻译质量 | 2020 |
| - | [173] | Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement | 采用迭代优化输出标记的方式,缓解非自回归模型的质量损失 | 2018 | |
| - | [118] | Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade | 针对全非自回归翻译,提出建模输出依赖关系的关键技术 | 2021 | |
| - | [347] | DePA: Improving Non-autoregressive Translation with Dependency-Aware Decoder | 设计依赖感知解码器,强化输出依赖关系建模,提升非自回归翻译性能 | 2023 | |
| - | [272] | Blockwise parallel decoding for deep autoregressive models | 引入单个前馈层,实现多未来位置的并行预测,再通过基模型验证最长有效前缀 | 2018 | |
| - | [257] | Accelerating Transformer Inference for Translation via Parallel Decoding | 将贪心自回归解码重构为非线性方程组,利用不动点迭代法实现并行解码,无需模型修改 | 2023 | |
| 边缘端设备相关论文 | TPU | [157] | TPU v4: An optically reconfigurable supercomputer for machine learning with hardware support for embeddings | 提出 TPU v4 架构,通过光学可重构设计支持机器学习,提供嵌入层硬件加速 | 2023 |
| FPGA | [336] | A Scalable GPT-2 Inference Hardware Architecture on FPGA | 设计适用于 FPGA 的可扩展 GPT-2 推理硬件架构,优化边缘端大模型部署 | 2023 | |
| 移动与边缘设备 | [79] | SpQR: A Sparse-Quantized Representation for Near-Lossless LLM Weight Compression | 提出稀疏量化表示方法,实现近无损 LLM 权重压缩,适配移动与边缘设备资源限制 | 2023 | |
| ASIC | [239] | Chiplet Cloud: Building AI Supercomputers for Serving Large Generative Language Models | 提出 Chiplet Cloud 架构,基于 ASIC 芯片组构建 AI 超级计算机,支持大规模生成式 LLM 服务 | 2023 | |
| ASIC | [367] | TransPIM: A memory-based acceleration via software-hardware co-design for transformer | 设计 TransPIM 架构,通过软硬件协同设计实现基于内存的加速,适配 Transformer 推理 | 2022 | |
| 新兴 AI 芯片(Apple M2 Ultra) | [172] | Relax: Composable Abstractions for End-to-End Dynamic Machine Learning | 提出 Relax 抽象框架,支持端到端动态机器学习,适配 Apple M2 Ultra 等新兴 AI 芯片 | 2025 | |
| 新兴 AI 芯片(AWS Inferentia) | [6] | Deploy Large Language Models on AWS Inferentia2 using Large Model Inference Containers | 提出基于 AWS Inferentia2 的大模型部署方案,通过推理容器优化芯片利用率 | 2023 | |
| 新兴 AI 芯片(SambaNova) | [28] | SambaNova Unveils New Chip the SN40L | 发布 SambaNova SN40L 芯片,专为大模型推理设计,提升边缘端 AI 计算效率 | 2023 | |
| 新兴 AI 芯片(Cerebras) | [81] | Cerebras-GPT: Open compute-optimal language models trained on the Cerebras wafer-scale cluster | 提出 Cerebras-GPT 模型,基于 wafer-scale 集群训练,适配 Cerebras 芯片的并行计算能力 | 2023 | |
| 新兴 AI 芯片(Graphcore IPU) | [16] | Dolly 2.0: Open-Source Language Model with ChatGPT-like Interactivity | 基于 Graphcore IPU 实现 Dolly 2.0 模型部署,支持类 ChatGPT 的交互式推理 | 2023 |
要不要我帮你导出这份包含边缘端设备论文的完整 Excel 表格,方便你按设备类型筛选、整理相关研究,或补充其他备注信息?
4. 算法优化之非自回归相关的论文
- 非自回归解码的综述论文
- A thorough survey on non-autoregressive translation [ 319 ]
- 非自回归解码相关的论文
- Non-autoregressive decoding [ 110, 117 , 122 ]
- 半自回归解码
- semi-autoregressive decoding [ 111],
- 迭代优化输出标记
- teratively refining output tokens [173 ].
- 对输出依赖关系进行建模
- modeling output dependencies [ 118 , 347]
- 块级并行解码
- Blockwise parallel decoding [ 272 ]
- 并行解码
- Parallel decoding [257 ]
| 分类 | 标注编号 | 论文标题 | 核心贡献 | 发表时间 |
|---|---|---|---|---|
| 非自回归解码综述论文 | [319] | A survey on non-autoregressive generation for neural machine translation and beyond | 系统总结非自回归生成在神经机器翻译及其他领域的最新进展 | 2023 |
| 非自回归解码相关论文 | [110] | Mask-Predict: Parallel Decoding of Conditional Masked Language Models | 提出掩码预测方法,通过打破词依赖实现并行解码,加速机器翻译 | 2019 |
| [117] | Non-autoregressive neural machine translation | 首次提出非自回归神经机器翻译框架,奠定并行解码研究基础 | 2018 | |
| [122] | Non-autoregressive neural machine translation with enhanced decoder input | 通过增强解码器输入,优化非自回归翻译的输出质量 | 2019 | |
| 半自回归解码及延伸技术 | [111] | Semi-autoregressive training improves mask-predict decoding | 提出半自回归训练方法,提升掩码预测解码的翻译质量 | 2020 |
| [173] | Deterministic Non-Autoregressive Neural Sequence Modeling by Iterative Refinement | 采用迭代优化输出标记的方式,缓解非自回归模型的质量损失 | 2018 | |
| [118] | Fully Non-autoregressive Neural Machine Translation: Tricks of the Trade | 针对全非自回归翻译,提出建模输出依赖关系的关键技术 | 2021 | |
| [347] | DePA: Improving Non-autoregressive Translation with Dependency-Aware Decoder | 设计依赖感知解码器,强化输出依赖关系建模,提升非自回归翻译性能 | 2023 | |
| [272] | Blockwise parallel decoding for deep autoregressive models | 引入单个前馈层,实现多未来位置的并行预测,再通过基模型验证最长有效前缀 | 2018 | |
| [257] | Accelerating Transformer Inference for Translation via Parallel Decoding | 将贪心自回归解码重构为非线性方程组,利用不动点迭代法实现并行解码,无需模型修改 | 2023 |